
記事の監修者
今回は、データ分析業務における前処理の重要性についてお話をしていきたいと思います。
データ分析業務の求人増加
昨今、データ分析業務における仕事の需要増加により、データ分析業務の求人は増え続けています。
その背景としてはビックデータを蓄積できる環境が技術的にも可能となってきたという点が非常に大きいです。
世界を代表するGAFAMとも呼ばれる企業集団もビックデータによる情報の利活用を駆使し企業業績を急拡大させています。
そのような背景からもデータ分析を行う人材の需要は今後も増えていくことが予想されます。
このコラムを読まれている方は、企業の収益アップや業務改善を行うデータ分析という仕事を将来的にやってみたいと思われている方も多いかもしれません。
データ分析は難しい?
データ分析というとなにやら難しそうでかつ誰もが知らないような知識と技術を駆使しているようなイメージを持たれている方も多いと思います。
しかし、実際の実務の現場におけるデータ分析業務は、データ分析を行いその結果を元に企業収益に即貢献していくというよりかは、そのデータ分析を行うまでの過程が非常に重要かつ泥臭い業務になっていることをご存知でしたでしょうか?
泥臭い業務という表現に疑問を持たれる方もいるかもしれませんので、ご説明していきたいと思います。
irisのデータセットについて
まずsklearnの標準モジュールであるirisのデータセットについてですが、sklearnを学ばれている方であれば一度はデータの中身を見たことがあるのではないでしょうか。

irisの説明変数データをデータフレーム化して見てみると以下のように表示されます。
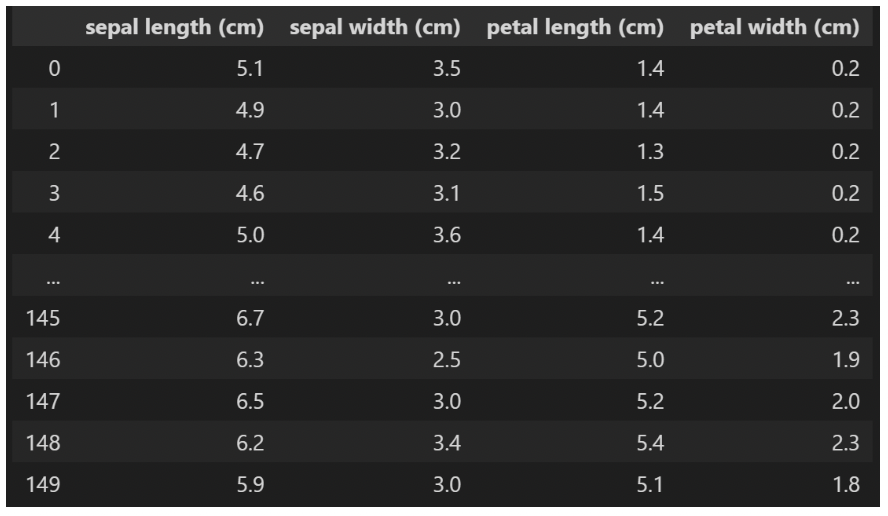
皆さんはこれを見てどのように思いましたか? おそらくデータ分析の初学者や実務経験がない方は、特に違和感を持たれなかったのではないでしょうか。
しかし、このirisのデータセットは非常にきれいなデータであり、このデータの状態のままsklearnの何かしらのモデルに組み込むことですぐにモデルを作成することが可能ですが、実際のデータ分析業務においては、そのような事はまずあり得ません。
というのもデータ上に欠損値が含まれていたり文字や数字が全角、半角で区別されていなかったり、変なところでカンマが入っているなどの問題によってモデルに組み込めないなどの問題が生じてしまうのです。
またirisのデータセットの統計量も見てみましょう。
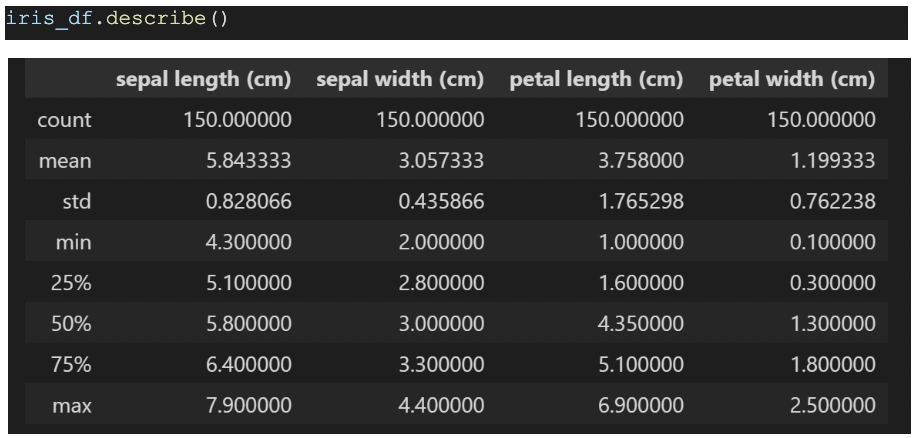
Sepal Length (がく片の長さ)の列を見ていただくと、がく片の長さの中央値(50%)が5.8%に対して最小値(min)が4.3cm、最大値(max)が7.9cmとそこまでデータ自体の偏りがないように見えます。
しかし、例えばこの最大値(max)に100㎝が入っていたらどうでしょうか?
中央値が5.8%に対して100㎝が入っていた場合、それはデータセットとしておかしい、もしくはデータに偏りがありロングテールの分布になっている可能性があることを疑わないといけません。
間違ったデータが入力されてしまったのか、はたまた季節性要因などの外れ値が入ってしまったのか、いずれにしても分析を行う前段階でそれらの処理をどのようにしなければいけないのか判断を求められることになります。
この工程を飛ばして、データ分析を行っても実務上の意思決定に影響を与えるような分析結果を出すことは困難であり、間違った分析結果を導き出した結果、予期せぬ自体を招く可能性も十分にあり得るのです。
従って、今後データ分析の学習をしていくにあたり前処理の重要性を理解した上で、学習していくことを強くおすすめします。
データの前処理が一番重要
さて、ここまでデータの重要性について書いてきましたが、学習を検討している方の中には「難しそう」とか、独学者の中でも何度も躓いてしまっている方もいるかもしれません。
テックアイエスのカリキュラムでは、講師との1on1を始めすぐに質問できる環境が整っています。
ぜひ、スクール学習も検討してみてくださいね。
テックアイエスの「データサイエンティストについて相談してみる」
全国どこにいても学べる!超優良のプログラミングスクールまとめました【国内完全網羅】現役エンジニアが厳選したおすすめのプログラミングスクール
自分の住んでるエリアでプログラミングスクールを探したい⭐️
エリア別で、おすすめのプログラミングスクールをまとめました。
ぜひ参考にしてみてくださいね。
北海道 / 東北
関東
群馬 / 栃木 / 埼玉 / 茨城 / 東京 / 千葉 / 神奈川
中部
福井 / 石川 / 岐阜 / 愛知 / 富山 / 長野 / 山梨 / 静岡 / 新潟
近畿
兵庫 / 京都 / 大阪 / 滋賀 / 奈良 / 三重 / 和歌山














